The following in an updated (though still initial) data model for an animal classification system. This system contains multimedia records for many types of animal. The system allows for the construction of a variety of classifications by using Node objects. By adding new classifications or exploring existing ones, users can examine a variety of relationships between animals. They can using alternate classifications, or even intersect different classifications, depending on their current information need. Users can be anyone with an interest in animal classification, from junior high students and amateur enthusiasts to researchers and zoological taxonomist's.
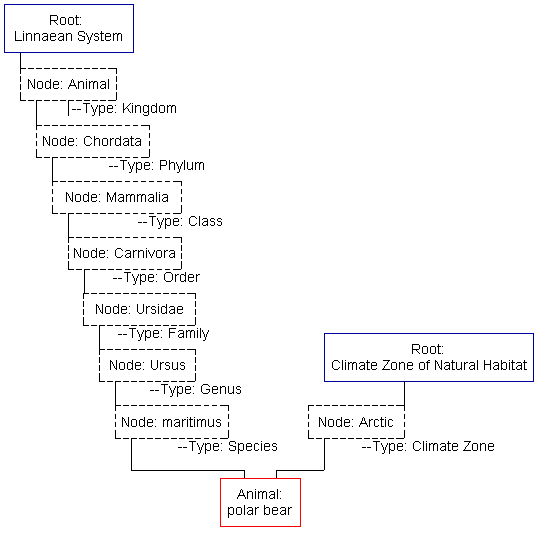
Because of the redundant/recursive use of nodes, this system can be a rather hard to imagine. Here's an example:
As you can see, the root-node architecture allows for the construction of practically any number of classification systems. There can be any number of node levels; indeed, the Climate Zone classification only uses one such level. (Other likely nodes may be "desert", "rain forest", "tundra", "marine", etc.) Also, I have only shown one branch here of a tree-like structure. At each level of the Linnaean System there are a number of other nodes--many Families under the same Order, many Species under the same Genus, etc. These systems all use the same animal records. (Not every classification system will use all the animal records, however; for example, perhaps someone wishes only to classify snakes on the basis of their venom and how they interact with known anti-venoms.)
Ideally, queries will be able to explore multiple classifications and combine the results. For example, imagine someone compiling a identification guide for marine mammals. Using only the Linnaean System, they would have to sift through all mammals in order to find groups such as whales and dolphins (Order="Cetacea"). Using only a Climate Zone classification that includes a "Marine" zone, they would be swamped with fish, sponge, coral, and other irrelevant animal records. However, if they could intersect these results, they would find whales and dolphins, as well as sea otters, dugongs, and other marine mammals not easily found traversing only the one classification system or the other.
Here are some other possible information needs that might be served by this system:
I hope these examples shed some light on the nature of this system.
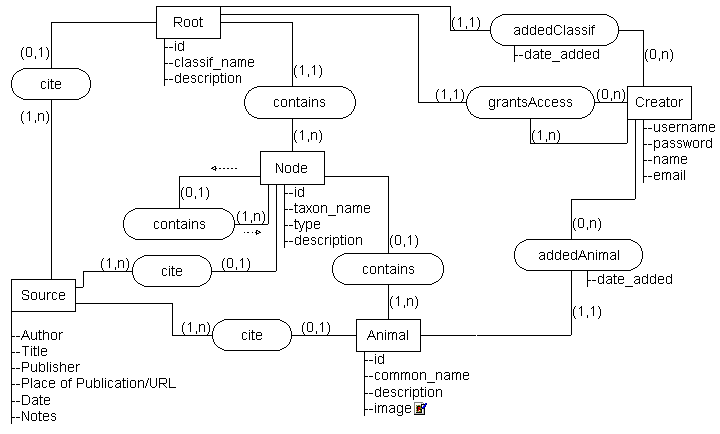
-- Complete SSM model --
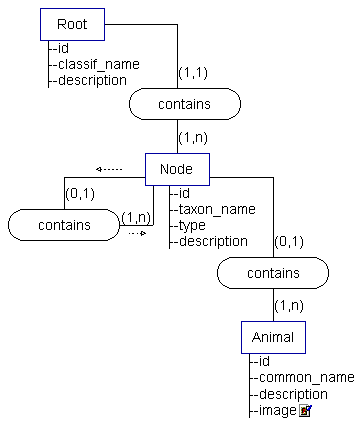
-- Detail of the core entities --
| Root | |
|---|---|
| id | <dec(10)> -- a unique system id for this entity |
| classif_name | <vchar(60)> -- the name of the classification system stemming from this root |
| Description | <vchar(1000)> -- a description of this classification system |
Root serves to placehold the top of a classification system. For example, the well-known Kingdom-Phylum-Order-Family-Genus-Species classification is known as the Linnaean System. If this system was being modeled, Root.classif_name would likely equal "Linnaean System".
| Node | |
|---|---|
| id | <dec(10)> -- a unique system id for this entity |
| taxon_name | <vchar(60)> -- the name of the particular taxon or group or classification level represented by this node |
| type | <vchar(40)> -- describes the type of taxon or the level within the classification system |
| Description | <vchar(1000)> -- a description of this entity |
The nodes will form the bulk of the classification structure and possibly be the most common record type in the database. Type serves to describe the level or taxon of the node. For example, if this were a node somewhere between a "Linnaean System" Root and a "polar bear" Animal record, the taxon_name may equal "Ursus" and the type equal "Genus." (It would then contain another node, taxon_name="maritimus" and type="Species", which would then contain the "polar bear" record.)
| Animal | |
|---|---|
| id | <dec(10)> -- a unique system id for this entity |
| common_name | <vchar(60)> -- the common English name for this animal. |
| Description | <vchar(1000)> -- a description of the animal, perhaps including such things as physical characteristics, habitat, main diet, etc. |
| image | <image> -- a picture of the animal type |
I have called this entity Animal, but there is no reason that plants or fungi or other types of life (or even non-life!) could not use this record in the same way. Currently, I'm keeping things simple by only having an image. Other options (in future versions of the database) include a video of the animal or an audio file of the call or sound it makes (this would be especially useful for birds).
The common name should correspond to a species level of granularity, as is the case in most animal identification guides. For example, "polar bear" rather than just "bear", "sea otter" rather than just "otter", etc.)
| Source | |
|---|---|
| Author | <vchar(50)> |
| Title | <vchar(120)> |
| Publisher | <vchar(60)> |
| Place of Publication/URL | <vchar(100)> |
| Date of Publication | <date> |
| Notes | <vchar(250)> -- notes or comments about this resource |
I think this is pretty clear. It's just your basic, simple bibliographic record.
| Creator | |
|---|---|
| Username | <vchar(15)> |
| Password | <vchar(12)> |
| Name | <vchar(50)> |
| Email Address | <vchar(30)> |
Creator is a user that can develop new classification schemes or add animal records. Originally I concieved of this entity type as a subclass of User. However, in an open access system, generic Users would not need passwords to simply query the system, nor would they have recordable relationships with the data. So there was no need for the entity User, and I removed it. Also, there may be a subclass of Creator called Administrator that can delete entities it did not create; I'm not sure of the necessity of such a class, so I have not included it either.
| contains (Root to Node) | |
|---|---|
| E1: Root | (1,1) -- A Root must contain some Nodes. |
| E2: Node | (1,n) -- One or more Nodes should be contained in this way. Ideally, there would always be at least 2 Nodes directly under a Root (2,n here), but I'm not certain I want to restrict that system by making that an actual requirement. |
| contains (Node to Node) | |
|---|---|
| E1: Node | (0,1) -- A Node may or may not contain other nodes. |
| E2: Node | (1,n) -- If it does contain Nodes, it can contain any number of them. (It can't contain itself, but I'm not sure how to note that in SSM notation.) |
| contains (Node to Animal) | |
|---|---|
| E1: CS Node | (0,1) -- A Node may or may not contain Animals |
| E2: Animal | (1,n) -- If it does contain Animals, it can contain any number of them. |
I have had it suggested that these three relationships should each have different names. I wonder, since the same meaning is present in each case: the parent (first entity) is directly above the child (second entity) in the hierarchy. One nice (possibly) feature with having the same relationship name coming from node is that the relationship, with its (0,1) cardinality, will point to either a group of node or a group of animals. I think this is the behavior I would prefer (if indeed that's how things would work). If it turns out that these really do need unique names, the next version of this project will likely contain the relationships "RcontainsN", "NcontainsN", and "NcontainsA".
I don't know how to state that a Node can have only one parent (something that is containing it). It can have either one Root or one Node as a parent, and not both at the same time.
| cite | |
|---|---|
| E1: Root, Node, or Animal | (0,1) -- An entity may or may not cite a source. |
| E2: Source | (1,n) -- If it does, it can cite any number of sources. |
Again, there exists a relationship with the same name between different entity types, though the relationship is of the same nature in every case. I may have to rename these, or I may revive the CS Entity entity type which is a superclass to Root, Node, and Animal, from v0.1.
| addedClassif | |
|---|---|
| E1: Creator | (0,1) -- A creator may or may not have produced a classification yet |
| E2: Root | (1,1) -- A creator creates only one classification at a time. |
| date | <date> -- The date the new Root was added. |
| addedAnimal | |
|---|---|
| E1: Creator | (0,1) -- A creator may or may not have written an Animal record yet |
| E2: Animal | (1,1) -- A creator creates only one Animal record at a time. |
| date | <date> -- The date the new Animal was added. |
| grantsAccess | |
|---|---|
| E1: Creator | (0,n) -- A creator not have granted any accesses yet; if he has, he can grant any number of them (related to the number of Roots he has created) |
| E2: Root | (1,1) -- Each set of access permissions is related to only a single Root. |
| E3: Creators | (1,n) -- A creator has to be granting access to at least one other creator, though any number is possible. |
The first two relationships help keep track of who authored what. The third allows the creator of an entity to give permission to other creators to edit or change that entity. There are a lot of similar possible relationships. See Appendix: Creator Relationships for discussion of this new can of worms.
Comments or questions are appreciated!
Thank you for reading this far! The following is a list of notes, comments and thoughts concerning current problems and future developments. Though not officially part of this report, comments on these points would be most helpful.
Adding the creator relationships has opened a whole new can of worms. How many should be included? For each classification entity (root, node, animal) should there be an Added, GrantsAccess, and Edited relationship? All this would record who created an entity (and when), and allow that Creator to declare who else can edit this entity or add other entities below this one. Then every edit would leave a record: who worked on which entities and when.
There are problems with scope, however. Suppose creator A creates a Root, and then grants access to that classification tree to B so that B can add Nodes. (Perhaps B specializes in a certain Family or Order and is taking over that part of the tree.) However, then B wants to grant access to C (her student assistant perhaps). If access is only by root or entire tree, C will have to get access permission from A. So it seems access will also have to be by Node. (This could get messy.) One things I don't think I want is for B to be able to pass on full Root access to C. This would violate A's creator privileges. So probably there will have to be GrantsAccess for nodes. So if B created a Node for a family, she would then have access-granting rights to that Node. So she could grant C permission, and C would be restricted to nodes beneath B's node. That would work.
All of this depends on what philosophy I'm going for. Who owns a classification scheme once it is in the system? If it becomes communal system property, then should any creator be able to add anything? (Remember, most users will be unable to change the system at all, only search it; so there has probably been some sort of screening even before a creator gets access to the system.) Perhaps simply recording additions and edits (who touched what when) would be deterrent enough to prevent the need for the GrantsAccess relationship. How vindictive are taxonomists? Is all this control excessive? Should any creator be able to freely access any classification scheme in the system?
Another question is where do sources come from? If creators add these as they are needed (cited by entities), should they too follow the same add, edit, and access rules?
All CS entities (root, node, animal) now share 3 attributes (id, name, description)(though I don't think id really counts) and a cite relationship to sources. If I go ahead with the add, edit, and possibly grantsAccess relationships for each for each CS entity, it may be simpler to bring back the superclass CS Entity. [See v0.1 for more info.]
I still need to decide whether a node can contain other nodes and animals at the same time. Taxonomies usually contain animals only at the leaves, and that is the direction I'm tending. However, as with file systems, it is sometimes nice to place things in a parent directory when they don't fit neatly in a sub-directory. Over time, these "lost" files may add up to form their own subdirectory.
Is the overlapping of the contains relationships (node-node OR node-animal) sufficient to guarantee that a node contains only other nodes or only animals? I think so.
Though nodes are no longer weak entities, there is still a need to keep resources managed in the system. The problem covers more than nodes, however. There may need to be some sort of garbage collection in the system to remove sources that are no longer cited, orphan nodes, and perhaps inactive creators.
Possible name: Maxx. This comes from the MTV cartoon series The Maxx. Maxx had a problem of shifting between two worlds. In the world of Outback, he was a powerful superhero; in our world, he was a homeless bum in a cardboard box. Other features and creatures besides Maxx were present in both worlds. In our world, a blimp; in the Outback, an air whale. This seems to fit nicely with a common underlying reality in this system (the animal records) viewed from different world viewpoints (classification systems).
If this system was ever implemented, it would be v1.0. Once it was patched and debugged and working at a basic level, it would be time to start thinking about enhancements and extra features. Here are some of those possible features:
| ~ztomasze Index:
LIS: Initial Data Model http://www2.hawaii.edu/~ztomasze |
Last Edited: 05 Oct 2001 ©2001 by Z. Tomaszewski. |